Chinese artificial intelligence startup DeepSeek has released what it calls its most capable models to date, DeepSeek-V3.2 and DeepSeek-V3.2-Speciale. The company claims the latest models can match the capabilities of OpenAI’s GPT-5 and Google’s Gemini-3.0-Pro.
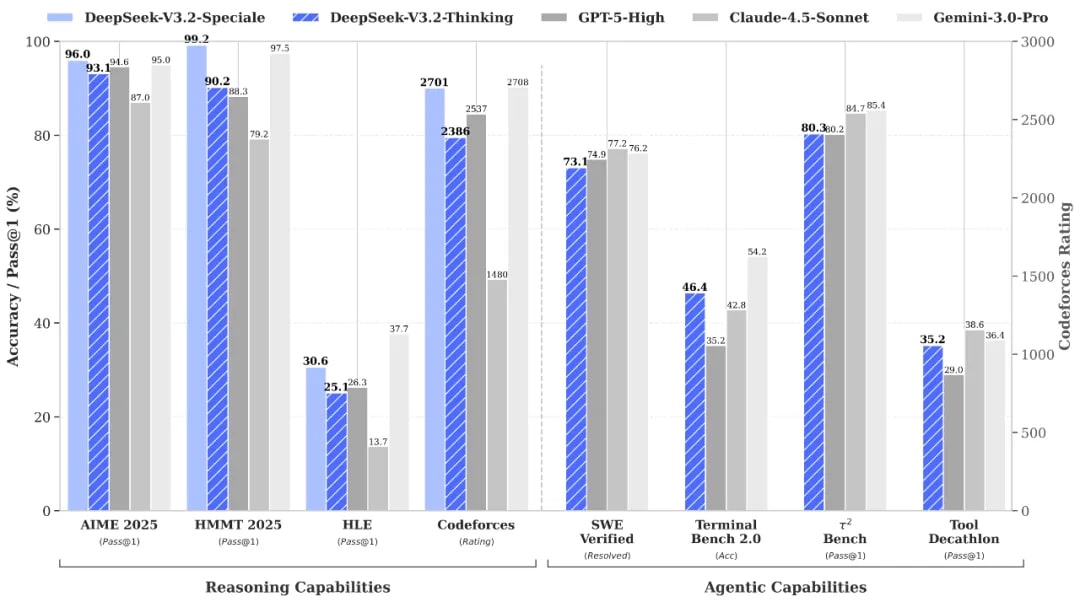
Notably, DeepSeek said V3.2-Speciale achieved “gold-medal performance” on an internal benchmark modeled on the International Mathematical Olympiad.
The launch extends a strategy that has defined DeepSeek’s rise this year: delivering competitive performance while reducing compute consumption through architectural efficiency. The new model integrates DeepSeek Sparse Attention (DSA), a proprietary mechanism designed to cut the computational load of processing long documents and complex tasks. DSA builds on DeepSeek’s V3.1-Terminus architecture and was tested through the experimental DeepSeek-V3.2-Exp model released in September.
Traditional AI attention mechanisms, the technology that enables language models to understand context, scale poorly as input length increases. Processing a document twice as long typically requires four times the computation. DeepSeek said its DSA approach breaks this constraint by using a “lightning indexer” that identifies only the most relevant slices of context for each query and ignores the rest.
According to the company’s technical report, DSA reduces inference costs by roughly half for long-sequence tasks. The architecture “substantially reduces computational complexity while preserving model performance,” DeepSeek wrote, estimating a 70% reduction in inference costs overall.
DeepSeek’s recent releases have consistently emphasized efficiency. Its V3 model, introduced in January, used a mixture-of-experts architecture that activated only a small portion of parameters per token. Rather than presenting V3 as a step toward larger systems, the company framed it as evidence that targeted routing could maintain capability while lowering operational requirements.
Shortly afterward came R1, which applies reinforcement-based training to improve reasoning and coding performance. Public disclosures indicated that R1 ran on older Nvidia H800 GPUs and was trained at significantly lower cost than many peer models. It gained traction among businesses because of its lower inference costs and flexible open-source licensing. Its release also contributed to growing momentum in open-source AI, alongside subsequent models from Alibaba’s Qwen and Tencent’s Hunyuan.
DeepSeek-V3.2 and DeepSeek-V3.2-Speciale can be viewed as a continuation of this path. The models target reasoning tasks and agentic workflows while aiming to maintain a relatively light operational footprint.
DeepSeek has drawn attention in part because AI deployment economics remain difficult. Even as investment in data centers and hardware accelerates, inference costs have not fallen enough to meaningfully improve margins. OpenAI, whose launch of ChatGPT helped catalyze the current AI wave, has yet to turn a profit three years on. Meanwhile, model sizes continue to grow, keeping operating expenses high for organizations deploying AI at scale.
This cost pressure shaped early adoption of R1. Companies integrating the model frequently cite its lower inference requirements as a key factor, particularly in sectors where latency and cost directly impact user experience and product margins.
RELATED ARTICLE

Energy consumption is another constraint. In several regions, data center expansion has raised concerns about power availability and environmental impact. Because inference accounts for a large portion of AI’s energy use, more efficient models can help reduce both cost and infrastructure strain. DeepSeek’s engineering choices speak directly to this issue by attempting to make advanced reasoning accessible without requiring large-scale hardware deployments.
While DeepSeek’s efficiency-centric approach offers clear benefits in cost and accessibility, it also introduces tradeoffs for organizations comparing its models to systems from OpenAI or Google. One is capability breadth: although DeepSeek’s models perform strongly on reasoning and structured tasks, they may not necessarily match the multimodal depth or end-to-end versatility of larger proprietary systems.
In multimodal use cases involving audio, images, video, or tool use, other alternatives remain compelling. For example, Kuaishou’s Kling AI has gained broad visibility in video generation. By contrast, DeepSeek’s Janus family of multimodal models, released last year, has not seen the same level of international traction. The more recent DeepSeek-OCR model, introduced in October, is focused primarily on long-context compression and efficiency through optical 2D mapping.
DeepSeek-V3.2 is available through the company’s web and mobile apps, as well as via API. DeepSeek-V3.2-Speciale remains API-only for now, and the company has not yet said whether it will be accessible through other channels.
As of October, DeepSeek’s mobile app had roughly 72 million active users globally, according to Aicpb.com.